

Summary
In May, we set out to build the best token research agent on the internet using only open-source models. Powered by our new SERA architecture (Semantic Embedding & Reasoning Agent), we are excited to announce SERA-Crypto:
- The #1 open-source AI agent on the DMind benchmark, ahead of Perplexity Finance and Gemini, while just behind Claude 4.5 and GPT-5 by <3%.
- The #1 agent on our internal live crypto analysis benchmark, beating all existing AI systems (open or closed)—GPT-5 Medium Reasoning, Grok 4, and Perplexity Finance.
Achieving state of the art performance, SERA-Crypto runs at a fraction of the cost and at good latency (under 45 seconds), solely utilizing an open-source stack of Qwen and GPT-OSS models. Most interestingly, it uses simple embedding match to call multiple tools in parallel and to reason about the data with dynamic prompting for the most relevant answer.
Given the growing demand from crypto exchanges, wallets, and DEXs to integrate new AI tools that are customizable and crypto-specific, we want to fully enable the developer community to build powerful crypto X AI systems. We have decided to open-source all SERA-related work over the next few months:
- Our crypto benchmark focused on in-depth analysis and research
- The SERA framework for building powerful reasoning agents
- The SERA-Crypto agent, customized on top of SERA for crypto use cases
Read on to understand what our benchmark measures, the advantages of SERA compared to common system like ReAct, and how SERA-Crypto is able to achieve state-of-the-art performance.
Benchmarks: How We Measured Success
DMind Benchmark
The DMind Benchmark is the first comprehensive benchmark for Web3-specific reasoning: spanning 9 categories (blockchain fundamentals, infrastructure, smart contracts, DeFi, DAOs, NFTs, token economics, memes, and security) through objective multiple-choice questions and subjective open-ended tasks.
The DMind team evaluated a range of major models (ChatGPT, DeepSeek, Claude, Gemini, etc.), showing that frontier models struggle with many areas like tokenomics, smart contract security flaws, and complex DeFi flows.
SERA-Crypto scores #1 among open-source agents and achieves overall state-of-the-art performance, outperforming Perplexity Finance, Gemini 2.5 Pro, Claude Opus 4.1, and GPT-o3. In its first iteration, SERA-Crypto is less than 2% behind the leading system GPT-5 Medium.
.png)
Our Internal Crypto Benchmark
The DMind Benchmark relies on discrete evaluation, where each query comes with an objective answer. However, this does not accurately capture the types of questions we were seeing in production.
We observed that many crypto users are interested in time-sensitive information, with data changing every minute without a single clear answer. To better test performance on this use case, we built our own benchmark tailored to token research, with a focus on evaluating AI’s ability to analyze large multi-source context inputs for answering open-ended crypto questions.
Our benchmark consists of 198 real user queries drawn from Sentient Chat traffic, grouped into 11 categories. The questions are often open-ended and require comprehensive industry understanding to provide a quality answer:
- Any trading tips for SOL?
- What’s happening in Solana DeFi today?
- who is backing $ASTER
- is it good to long $APT now?
- Are ETH gas fees spiking this week?
The table below provides the distribution of queries by category:
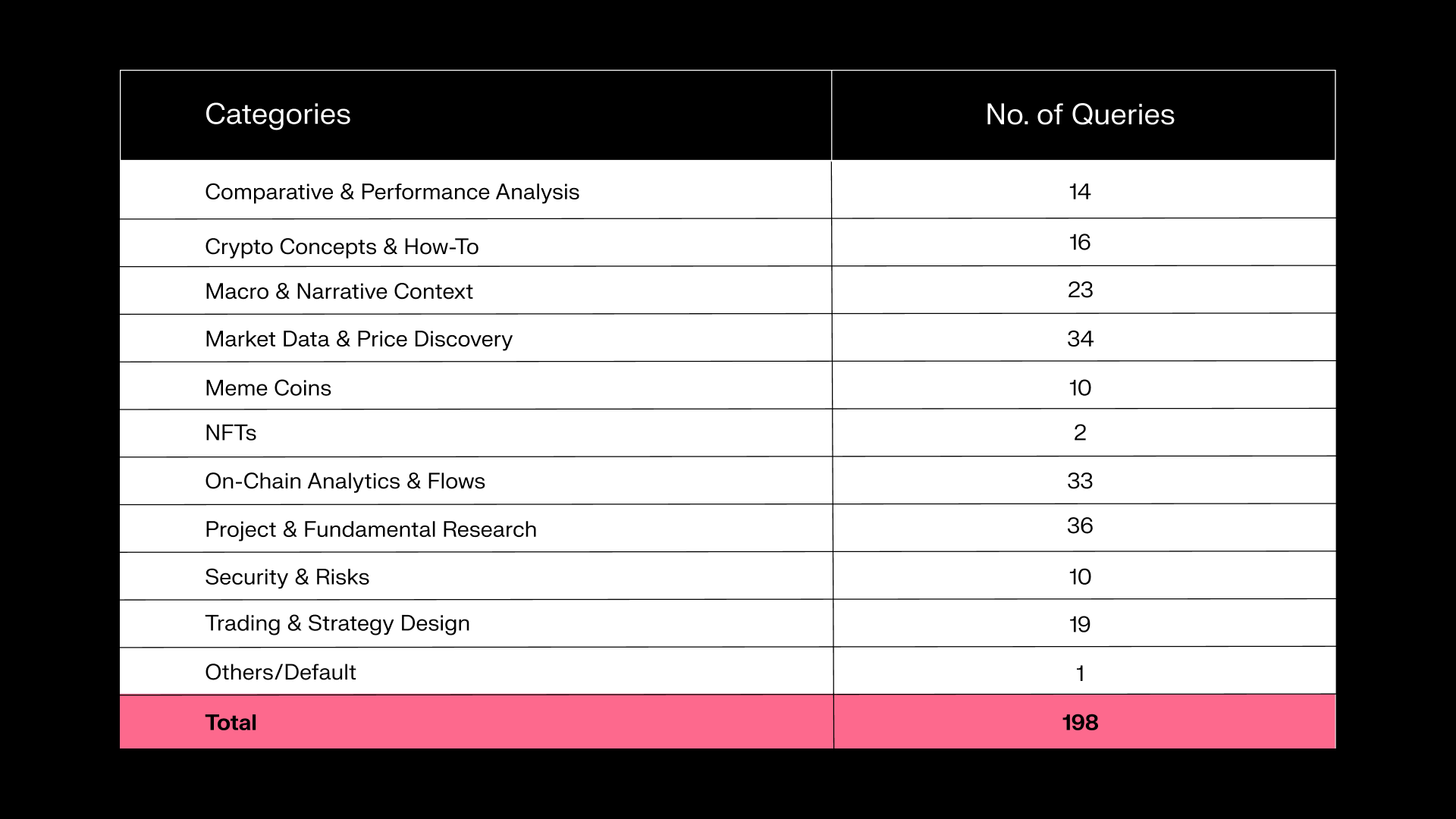
For evaluation, each of the 198 queries is scored by a strong long-context reasoning model—DeepSeek v3.2. It rates every answer from 1 to 10 across four crypto-focused criteria: relevance, depth, temporal accuracy, and data consistency.
SERA-Crypto achieves top performance on this benchmark:
- #1 overall combined score
- #1 on relevance and temporal accuracy
- 3% behind #1 on data consistency
- 8% behind #1 on depth
This benchmark illustrates SERA-Crypto’s state-of-the-art performance for real crypto token research sourced from users. Even as an open-source system, we outperform expensive closed-source alternatives like GPT 5, Gemini 2.5 Pro, Grok 4, and Perplexity Finance.
.png)
Judging happens in a conversational format, where the model sees the earlier questions in the thread but never sees any answer metadata or model names, reducing scoring bias and maintaining evaluation consistency. This also reduces positional bias, since the first answer’s score becomes a stable reference point for all later scoring.
Note: Even with conversational judging and hiding all answer metadata, recent work shows that some model bias may still be inherent. We have already started developing a more neutral LLM-as-a-jury system to further improve evaluation fairness and will be able to release updated results in a few months.
SERA: New Architecture for Fast Reasoning via Embeddings
Our latest architecture combines the reasoning and tool-calling capabilities of powerful ReAct systems without sacrificing latency.
In SERA, we utilize embeddings instead of an LLM, for efficient and consistent routing/reasoning. Every input query is rephrased, embedded, and then compared against two separate embedding indexes: one for tools and one for prompt templates.
Our crypto agent’s tool index contains descriptions for the 50+ endpoints supported: market data APIs, TVL trackers, on-chain flow providers, derivatives feeds, social and sentiment APIs, scraped data from X handles, etc. The prompt index contains short descriptions of our 11 crypto query categories and their associated templates.
At a high level, SERA behaves like this:
tool_index = build_embedding_index(
{tool.name: tool.description for tool in TOOL_REGISTRY}
)
prompt_index = build_embedding_index(
{tmpl.name: tmpl.description for tmpl in PROMPT_TEMPLATES}
)
def sera(query):
q_vec = embed(query)
# Select tools
tool_names = top_k(tool_index, q_vec, k=K_TOOLS) # e.g. 8–12 tools
tools = [TOOL_REGISTRY[name] for name in tool_names]
# Fill parameters and call the tools
...
# Select prompt template
prompt_name = top_k(prompt_index, q_vec, k=1)[0]
prompt_template = PROMPT_TEMPLATES[prompt_name]
# Synthesize data
...
Using an explicit thinking framework, a reasoning model synthesizes the tool outputs and selected template into a final answer.
By off-loading routing and prompt generation to embeddings, SERA avoids long ReAct loops, selects the same tools consistently for different query categories, executes multiple tool calls in parallel, and reasons about the answer—keeping average latency under 45 seconds.
Note: Prior work explored verbalized sampling, which involves generating a distribution of possible answers to increase creativity, but this introduced unwanted variability and reduced consistency in the final responses.
SERA-Crypto: SERA Applied to Token Research
SERA-Crypto is the concrete agent instantiation of this architecture for crypto analysis:
- Extracting Intent: A query passes through an LLM-based rephraser to understand what the user is truly asking.
- Coin Resolution: A dedicated coin resolver disambiguates token tickers to avoid mixing unrelated projects.
- Embedding Routing: SERA’s embedding router selects tools and prompts. For a question like “How exposed is Lido to stETH de-pegging risk over the next six months?”, the tool index will prioritize TVL and staking APIs, on-chain flow providers for ETH and stETH, derivatives data for funding and open interest, and news/search endpoints around liquid staking derivatives. The prompt index will route the query to a “security and risk” or “fundamental research” template rather than a single generic one.
- Parallel Execution: While the selected tools fetch live data from APIs, our open-source deep search layer expands the user query to retrieve relevant data from protocol docs, governance proposals, risk reports, dashboards, and curated articles.
- Optional Loop: If the query was too open-ended (e.g. “Which are the top 5 tokens to give me highest ROI in the next 30 days?”), another round of tool calls is executed to ensure we get the latest data about the tokens returned from search.
- Final Response: Once all data is returned, the final reasoning step synthesizes context into clear insights.
.png)
We optimized embedding-based matching through building tool sets and reasoning prompts from our initial ReAct prompt and iterating. Currently, our dynamic prompt directory contains 11 different prompts to cover each query category and a general prompt reserved for broad analysis:
- Market Data & Price Discovery
- Comparative and Performance Analysis
- Trading and Strategy Design
- On-chain Analytics and Flow
- Project and Fundamental Research
- Macro and Narrative Context
- How-to-Concept Explainer
- Meme Coins Explainer
- NFTs Explainer
- Security and Risks
- Default / General Analysis
Each prompt is tailored to its query category but uses a simple, general reasoning pattern. This keeps answers thorough and research-oriented for market questions, while still giving clear, actionable suggestions for trading predictions.
Although creating these prompts can feel overwhelming at first, we see it as the cost of making end-to-end AI systems more reliable, especially with such a wide range of user needs. Internally, we are already building tools to automate this process so SERA-Crypto can generate and deploy customized prompt templates quickly for any exchange, wallet, or crypto platform.
The SERA-Crypto Stack
All of this runs on a fully open-source model stack:
- GPT-OSS-120B for reasoning and summarization
- Qwen3-Next-80B-A3B-Instruct for tool calling
- Qwen3-Embedding-8B for embeddings
We did not utilize closed models, closed-source search tools, no fine-tuning, or any other optimization methods. The SOTA performance comes solely from good architecture and engineering.
We spent a great deal of time deciding which API providers to integrate for each data type, and harmonizing them under SERA was challenging. Here are some of the lessons we learned in this process:
- Building a reliable crypto agent requires an internal data layer for two key sources: project X accounts and official websites. Search alone was not enough for questions about partnerships, upcoming events, or fundamentals like tokenomics, products, and research papers.
- Many APIs either duplicate each other, return overly raw data, or become too expensive when combined. Optimizing this API surface is essential to provide full coverage across liquidity flows, whale activity, sentiment, and more, so the LLM can produce holistic answers.
- In the final summarization step, models—especially open-source ones—often mix older search results with up-to-date API data. To prevent this, we strongly recommend tightening instructions so the LLM always prioritizes API data. If needed, teams should even consider a “whitelist-only” model restricting which sources the search tool is allowed to pull from.
The end result of our work is a crypto agent that effectively coordinates 50+ APIs within one medium-latency open-source system, synthesizing real-time data behind paywalls, freely available to users.
As our Sentient Chat users continue to provide feedback, we continue expanding the use cases and data access of SERA-Crypto.
Pursuing Deeper Reasoning
SERA-Crypto delivers state-of-the-art performance while remaining fully open-source, low-cost, and much faster than heavier systems from OpenAI, Google, or xAI.
Although our first iteration already performs exceptionally well, there are many ways to push it further. Increasing our latency budget alone would unlock significantly higher performance, and our earlier research gives us a large set of ideas to build on. After SERA-Crypto and having built a solid, foundational “Crypto Research Agent”, the next step is building a “Crypto Deep Research Agent”:
- ReAct produced strong, insightful answers but lacked consistency. Adding a self-consistency validation layer and giving it more time to reason, reflect on tool-calls, and refine intermediate conclusions could significantly boost performance.
- Our previously released multi-agent reasoning architecture ROMA uses recursive task decomposition to build an execution graph of sub-tasks, enabling dozens of tool-calls and allowing it to generate stable, report-quality answers.
- SERA-Crypto currently runs a single cycle of search and tool-calling (2 cycles for open-ended questions). This allows for large coverage of production queries which are mostly open-ended and exploratory in nature while keeping latency reasonable. However, this limits the agent's ability to go further in-depth when needed. Introducing iterative or recursive reasoning steps, alongside a more light-weight search, would allow the system to handle much more complex research tasks.
Over the next few months, we will be exploring various ideas like these to advance the frontier of open-source AI, for crypto, search, and other domains!
What’s Next
SERA-Crypto and the SERA architecture were built on top of real usage from the Sentient community:
- 290K+ unique users
- 22M+ queries
- ~50K monthly active users during closed beta
Using this traffic, we efficiently solved issues in latency, coin resolution, search quality, and tool orchestration, exploring new research ideas and engineering innovation.
Over the next few months, we will:
- Open-source SERA and our internal Web3 & DeFi benchmarks, so anyone can reproduce, fork, or adapt our work.
- Tackle more difficult reasoning tasks like improving open-source search, ensuring answer factuality, and experimenting with more complex reasoning architectures
- Advance new reasoning systems for other domains (consumer finance, research, and more)
With SERA, we have shown that open-source AI can match closed-source systems for serious crypto research, all thanks to the Sentient community and Sentient Chat as their testbed.
Try SERA-Crypto today on Sentient Chat at chat.sentient.xyz.








