

Summary
Modern research copilots operate in environments where ground truth is ill-defined, multi-sourced, and continuously changing. In crypto analysis (and other data-intensive domains), users ask open-ended, time-sensitive queries and expect long-form, analyst-grade responses that coherently synthesize market data, on-chain signals, protocol fundamentals, and social narratives, while remaining temporally fresh, internally consistent, and decision-relevant.
We introduce CryptoAnalystBench, a benchmark for evaluating crypto AI agents designed to produce long-form analytical answers. The benchmark consists of 198 real production queries sampled from Sentient Chat and employs an LLM-as-a-judge rubric to score responses across four analyst-aligned dimensions: relevance, temporal relevance, depth, and data consistency.
We see CryptoAnalystBench as a reference for creating research chatbot benchmarks when AI development requires fast iteration, representative coverage of production traffic, regression detection, and actionable error analysis. The benchmark is meant to be complementary to ground-truth benchmarks and factuality evaluations.
In this blog, we outline the evaluation gap for reasoning AI systems, describe our methodology for constructing CryptoAnalystBench from production traffic, reveal our results from iterative building, and propose future work on factuality evaluation, systematic error analysis, and automated agent improvement.
Introduction: The AI Evaluation Gap
The current crypto and Web3 benchmarks base their success criteria on short, discrete tasks (1–2-step data retrieval and computation). With modern LLMs rapidly improving through tool-calling and planning capabilities, the difficulty bottleneck has shifted from “What is X?” to “Why is X?”
CryptoAnalystBench was built to address the portion that LLMs are now struggling with, focusing on questions that:
- are open-ended (ex. “Any trading tips for SOL?”)
- require rapidly moving market context (ex. “give me technical analysis of BTC and suggest a trade”)
- imply uncertainty and source prioritization (ex. “how do people feel about ETH now?”)
The Need for Comprehensiveness
CryptoAnalystBench is meant to be used in conjunction with ground-truth benchmarks for evaluating crypto AI systems. Accuracy and insightfulness combine for an effective answer. An answer can be technically “correct” but unhelpful (lacking insight). A seemingly insightful answer may be based on incorrect information due to tool-calling inconsistency or hallucinations.
Therefore, this benchmark is most effective when its results are analyzed in conjunction with answer correctness.
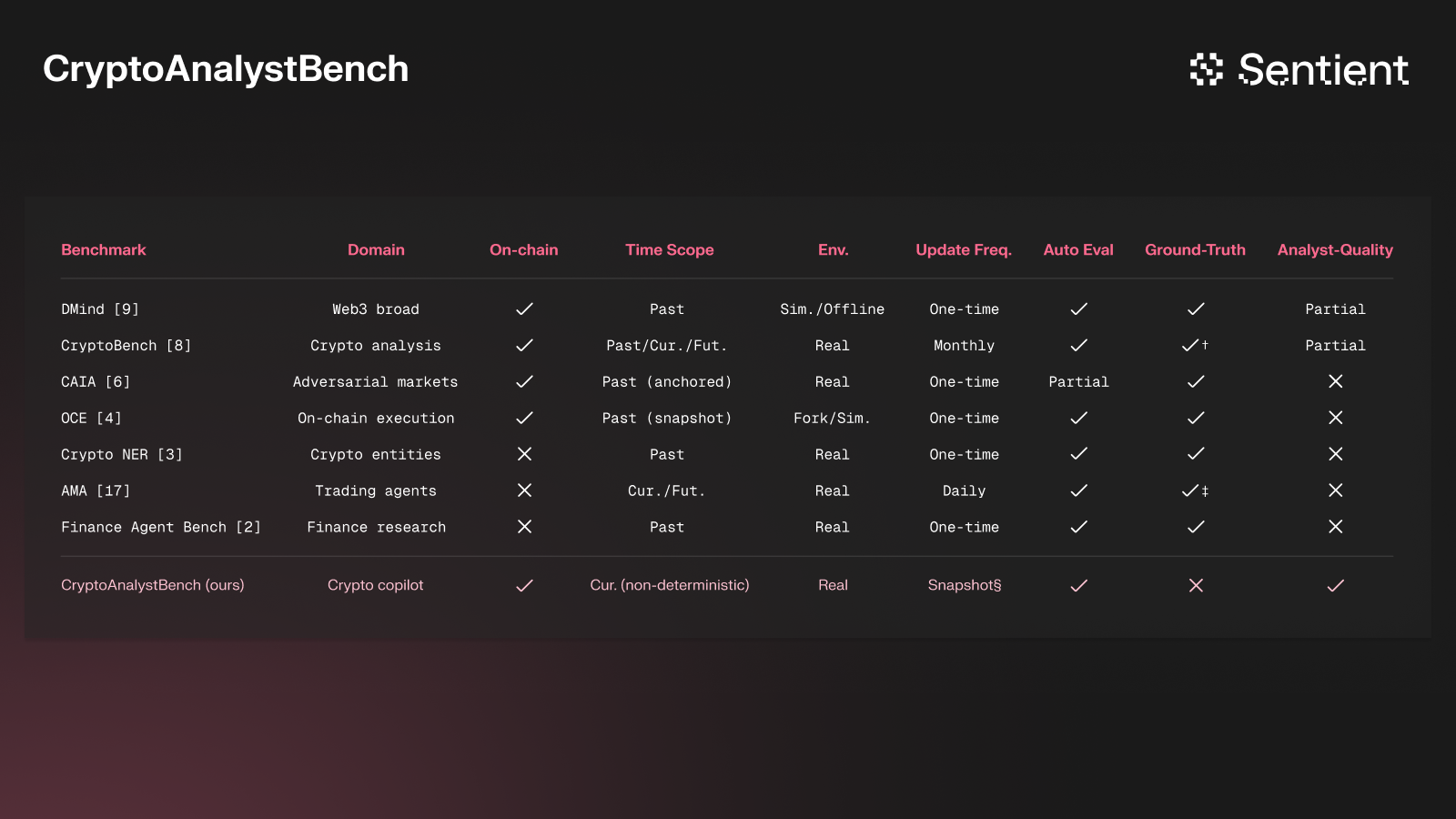
- Benchmarks like DMind or CryptoBench to assess tool-use reliability and scope.
- CryptoAnalystBench to measure the quality of long-form analysis.
- Factuality checks to catch hallucinations, incorrect citations, and wrong claims (we discuss how this is another major gap later in the blog).
The Need for Utility
This benchmark also provides a fast development aid for teams maximizing chatbot ROI from their sprints. Building an open-source or cheaper “specialized copilot” requires tight feedback loops from a benchmark that
- Reflects your traffic distribution
- Yields diagnostic signals aligned with user expectations
- Catches regressions after changes
- Quickly exposes major improvement areas for fast iteration
We built CryptoAnalystBench to capture these aspects, enabling teams to more easily build specialized AI systems.
Benchmark Construction
Through millions of real user-queries in Sentient Chat, we derived CryptoAnalystBench, reducing raw traffic into a compact benchmark in 5 stages:
- Filtering: Extract a small 4500-query slice of recent production data and filter out overly long (often summarization) and overly short (2–3 word) prompts.
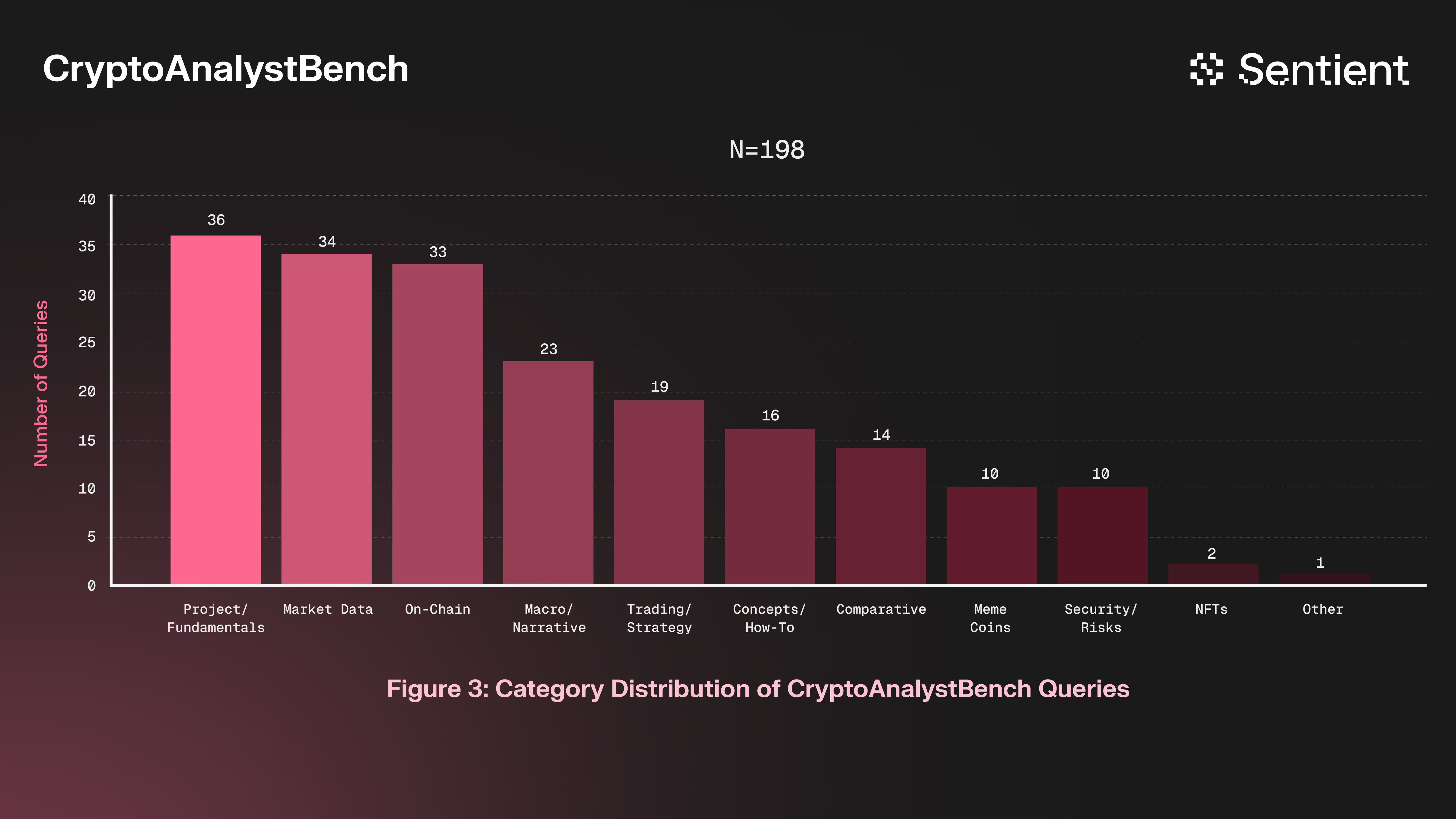
- Clustering: Group the remaining queries into semantic clusters, define 11 high-level categories, and tag each query with one of 11 categories using AI.
- Distillation: Condense near-duplicate prompts for a unique subset of queries (ex. “What’s up with POL” and “What’s up with BELDEX”) within each category (yielding ~650 queries) using an LLM.
- Pruning: Remove “easy” queries where all models perform well (mostly parametric-knowledge questions like “what is a token?”), reducing further to ~350.
- Curation: Hand-curate to a representative set (~198 queries) matching the proportions of the original, unfiltered traffic.

Through this process, we created a benchmark of 198 queries spanning 11 categories, capturing the wide variety of investment-relevant intents observed in our production traffic (e.g., market data and price discovery, on-chain analytics and flows, project and fundamental research, etc.).
Evaluation
User-Defined Criteria
Through user interviews with crypto traders and analysts, we isolated four analyst-aligned dimensions relevant to any long-form research AI agent. In development iterations, we used LLM-as-a-judge to score responses on the following dimension from 1-10:
- Relevance: directness in addressing the user’s intent and decision context.
- Temporal Relevance: freshness of used data relative to the evaluation date.
- Depth: comprehensiveness, technical detail, and multi-axis coverage.
- Data Consistency: internal data coherence and absence of contradictions.
Our **official GitHub repository** contains the exact descriptions used for each of these dimensions in the LLM judge prompt.
LLM Judge Selection
The judge model used for all reported results is DeepSeek-v3.1 (671B) (served via Fireworks). We experimented with alternative judges, including GPT-5 and Grok-4, but observed systematic response-specific biases—most notably verbosity bias favoring responses from the same model family. Across repeated runs and randomized response orders, DeepSeek-v3.1 exhibited the most stable and neutral scoring behavior, leading us to fix it as the judge for all experiments. We do not tell the judge which model generated which response and run the judge at low temperature (T = 0.1) with a large output budget, enforcing strict JSON-only outputs.
Evaluation Protocol
To assess multiple agents simultaneously, we judge candidate responses within a single shared judge conversation to minimize calibration drift across responses of the same query.
The structured LLM judge prompt for each query includes:
- the original user query
- the candidate response
- the response timestamp
- and previous responses in the conversation (if present)
The numeric score for each of the four dimensions and a short justification is returned in a fixed JSON schema for each query (example provided below):
.png)
Controlling Positional Bias
LLM judges are known to exhibit order effects, such as anchoring on the first response shown. To mitigate this, we apply balanced response-order randomization. For each query and the set of evaluated systems, we rotate through permutations of response order so each system appears equally often in each position, reducing confounding effects due to presentation order.
In the future, we hope to automate the precise scoring rubric and example creation such that LLM judges can score answers reliably without anchoring.
Ranking and Aggregation
After scoring all responses for a query, the judge produces a per-query ranking of evaluated systems based on the four dimensions, along with an overall rationale.
For a batch of evaluated agents, we report:
- mean scores per agent for each dimension and their total
- mean rank per agent and individual Rank 1-4 counts
- category-wise breakdowns
This setup supports multi-system comparisons as well as fine-grained slice analysis across query types.

Outcomes
Through CryptoAnalystBench, we could rapidly evaluate our system’s failure modes, spot performance gaps (compared to frontier systems like Grok, ChatGPT, Gemini, etc.), and produce our latest agent (**SERA-Crypto—**hosted as the default agent on Sentient Chat).
We intentionally chose a smaller benchmark dataset (~200 queries) to minimize evaluation time between AI updates without losing the representation of production traffic.
We prioritized the highest ROI AI improvements by looking at:
- query categories and dimensions where our scores were lower than the competitors
- AI-written explanations for why our scores were low
As with any agent engineering process, we used one of four levers to iterate:
- Prompt optimization
- Adding or changing tools
- Model selection
- Architecture improvement
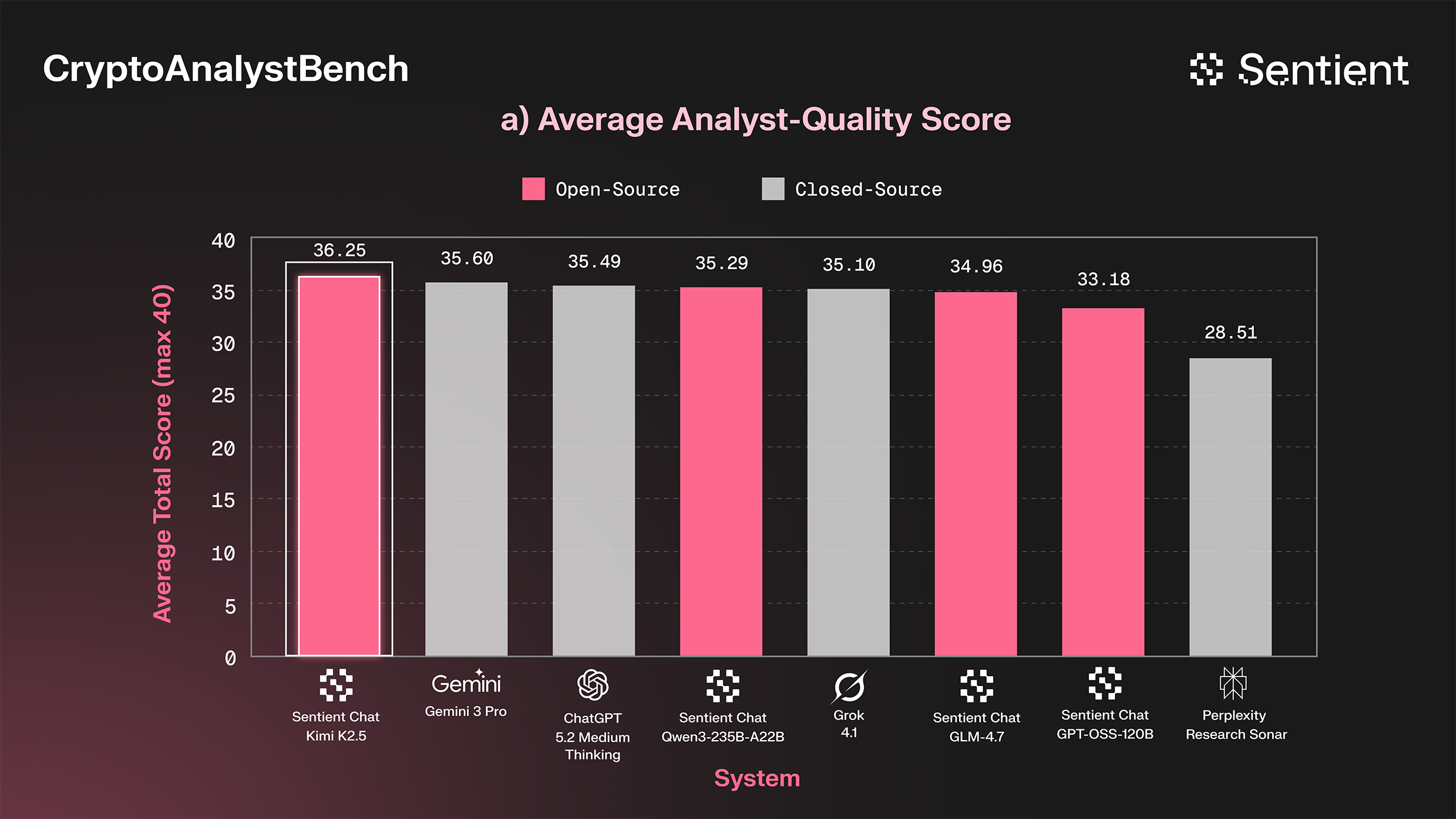
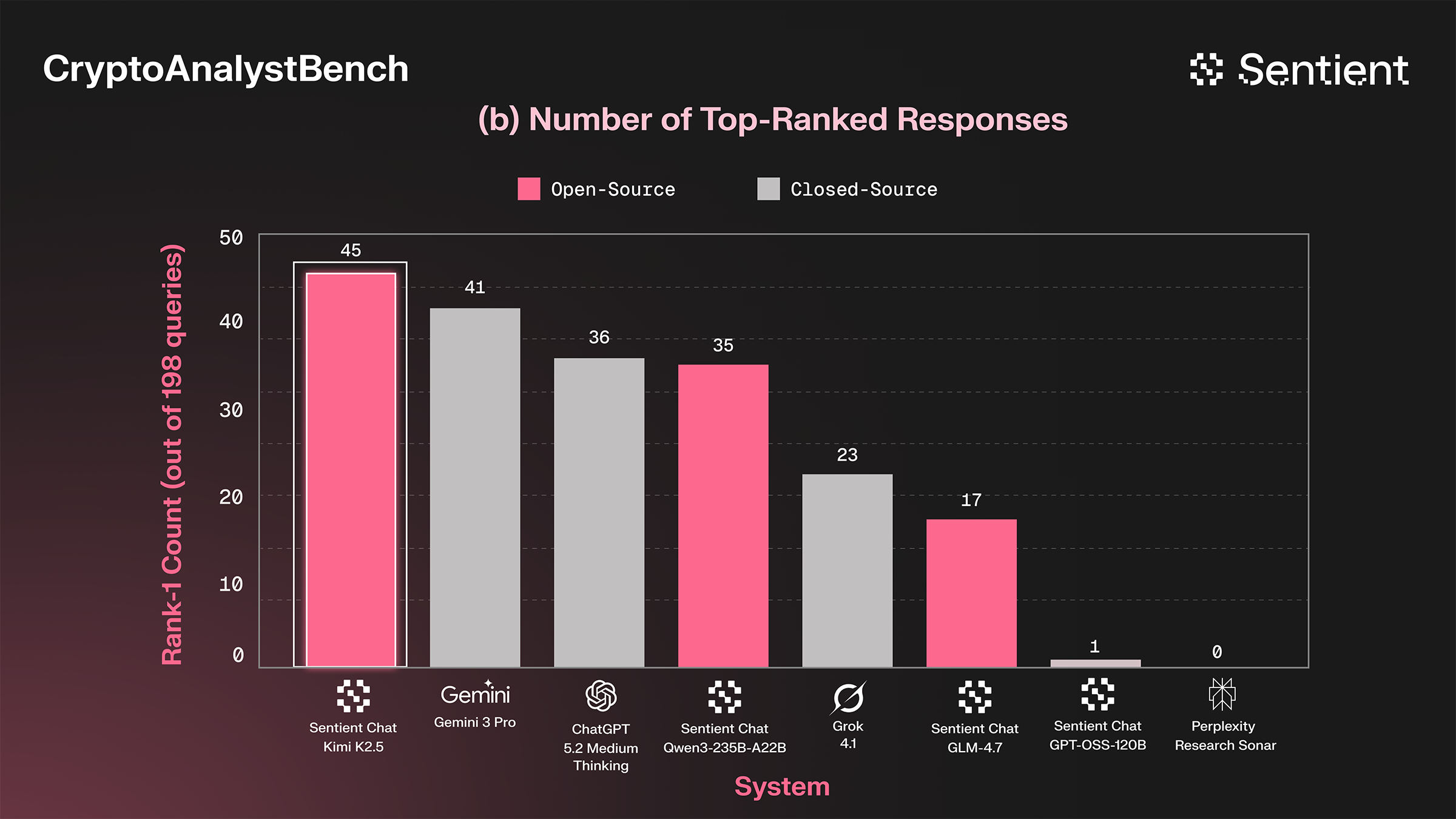
We used these levers to improve our open-source agent’s performance, raising its capabilities to that of frontier closed-source systems in the span of a few weeks. At a fraction of the cost, our completely open-source agent matches the performance of Gemini 3 Pro and GPT-5 Medium (powerful, high-latency systems).
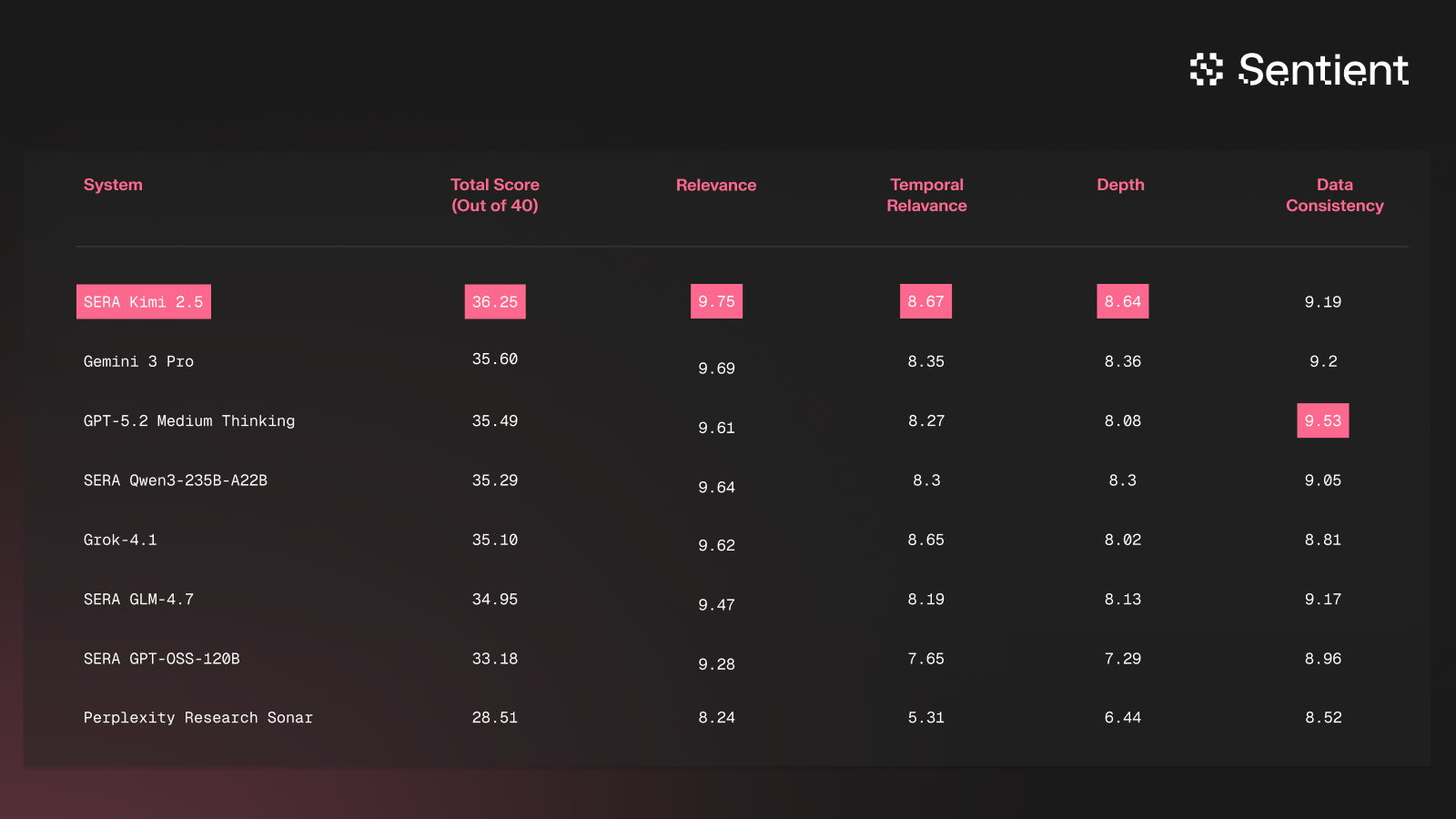
For those interested in using AI for crypto research, we observed generally high scores across the majority of tested systems, with SERA Kimi K2.5 in the lead, followed by Gemini 3 Pro and GPT-5.2 Medium, although GPT-5.2 Medium is the best in data consistency.
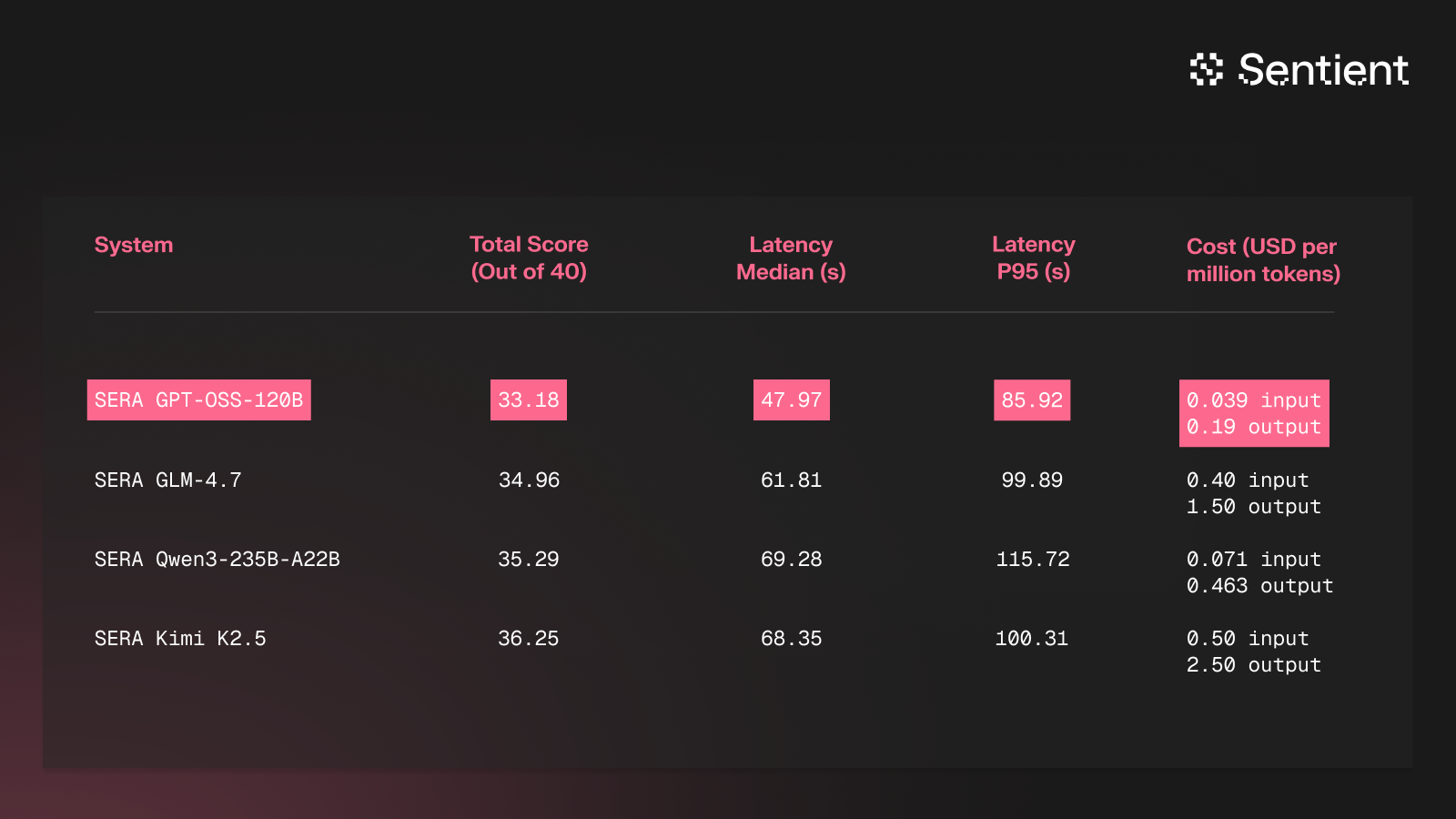
We also used CryptoAnalystBench to choose the reasoning model for the final version of our agent. After testing a few models in a fixed agent framework (SERA), we chose GPT-OSS-120B to balance cost, latency, and performance.
Observations from Frontier Systems
Through this process, we accumulated a substantial amount of AI-labeled data and noticed a set of common failure modes across different AI systems (especially clear across repeat runs).

All systems still struggle with hallucinations and citation issues, especially related to analysis rather than simpler search tasks. In long-form responses comprising dozens of factual claims, there is still no benchmark that can fully ensure or test comprehensive factual accuracy.
Future Work
Maintaining Freshness
The released CryptoAnalystBench is a condensed snapshot of our production traffic from November 2025. In the future, we want to automate its regeneration on a regular cadence, ensuring that queries are not stale and reflect current market trends across categories. We invite others to replicate our process and create your own benchmarks most relevant to your product.
Automated Error Localization and Remediation
We resolved a significant portion of errors detected by CryptoAnalystBench through basic trial-and-error methods. To address this limitation, we propose a granular analysis of execution traces across the full agentic pipeline, including reasoning, tool invocation, and data synthesis. This approach enables precise error localization while significantly reducing the need for human oversight. Moreover, it supports the automated generation of corrective interventions—such as prompt optimization, model substitution, or architectural modification. At a fundamental level, this shift emphasizes process evaluation over purely outcome-based evaluation.
More Rigorous Factuality Evaluation
While benchmarks like CryptoAnalystBench improve overall grounding, no comprehensive factuality harness exists—within crypto or elsewhere. Even leading systems such as Gemini and ChatGPT continue to hallucinate and produce incorrect claims.
To address this, we are building an evidence-bounded factuality layer that verifies claims against retrieved sources and their timestamps, and applies cross-run consistency checks to detect numeric drift, hallucinations, and unstable conclusions across repeated executions.
Conclusion
In this blog, we introduced CryptoAnalystBench, a benchmark for evaluating long-form analytical answers produced by AI agents in the crypto domain. Unlike benchmarks that focus on short, discrete data retrieval, CryptoAnalystBench targets the kinds of open-ended, time-sensitive questions users actually ask in production. It evaluates responses along analyst-relevant dimensions such as relevance, depth, temporal accuracy, and internal data consistency.
In practice, CryptoAnalystBench provides clear, actionable signals. It helps differentiate agent behavior, surface common failure modes, and guide iterative improvements. But it also reveals an important gap: strong performance on analyst-quality or ground-truth benchmarks does not guarantee factual correctness in long-form answers, especially when those answers include many numeric and time-sensitive claims.
We view CryptoAnalystBench as a complement to existing ground-truth benchmarks, not a replacement. Looking ahead, we believe long-form AI agents will require an additional, evidence-based factuality layer—one that verifies claims against sources and checks for consistency across runs. Together, these approaches are a necessary step toward building AI systems that users can trust for real-world crypto research and other data-intensive domains.









